About
- Courtney C. Mumma
- tdr-steering
- Caleb Holland (Unlicensed)
About the Texas Data Repository
The Texas Data Repository is a platform for publishing and managing datasets (and other data products) created by faculty, staff, and students at Texas higher education institutions. The repository is built in an open-source application called the Dataverse software, developed and used by Harvard University.
The repository is hosted by the Texas Digital Library, a consortium of academic libraries in Texas with a proven history of providing shared technology services that support secure, reliable access to digital collections of research and scholarship. For a list of TDL participating institutions, please visit: http://tdl.org/members.
Why deposit data in the Texas Data Repository?
To comply with funding requirements. The Texas Data Repository can help you comply with funder mandates data archiving and sharing, and gives you resources for developing data management plans and grant applications.
To ensure reliable, managed access for data. The Texas Data Repository gives you a convenient and reliable place to collect and share your data. And by depositing data there, you benefit from the TDL’s focus on long-term access and preservation of your content.
To increase scholarly impact. By publishing your data in the the Texas Data Repository, you give your data a DOI, making it easy for others to cite reliably.
To collaborate with research teams. Some situations may necessitate restricting access to data, at least for a period of time. The Texas Data Repository allows you to share your data with a select group of colleagues, version your data, and publish it when you’re ready.
To have access to local support through your institution’s library. Along with robust technical support from the Texas Digital Library, you can rely on trained librarians at your home institution to assist with multiple phases of the research cycle, including data management planning, preparation for data publishing, and long-term curation.
What to deposit (and not to deposit) in the Texas Data Repository
The short and sweet version:
- You can deposit data in any file type.
- You can deposit data from any research discipline.
- You can edit the license that governs re-use of the data. (CC0 is the default.)
- You cannot deposit data that contains confidential or sensitive information.
The longer version:
- Researchers can deposit a wide variety of data and related electronic materials to the Texas Data Repository, including spreadsheets, sensor and instrument data, surveys, GIS data, and imagery, along with associated material such as codebooks or data dictionaries. Any individual file uploaded to the repository must be under 4GB, though any uploads over 2GB, and some below that threshold, may be slow or stall due to variables outside of TDL's control. Please email support@tdl.org if you having trouble uploading files. If you have files over 4GB, we will consider support options on a case by case basis and in consultation with your Institutional TDR liaison.
- The Texas Data Repository encourages data deposit from all disciplines and can accept any type of data file, though it is advisable to provide data in non-proprietary formats in order to ensure broader use for researchers with access to different analytic software.
- By default, published data is assigned a CC0 license, so that others may freely access and build upon the work. Researchers can alter this license and create custom terms of use for their data if appropriate.
- The Texas Data Repository does NOT accept content that contains confidential or sensitive information, and requires that contributors remove, replace, or redact such information from datasets prior to upload. Confidential or sensitive information refers to all identifiable information, such that re-identification of any subjects from the amalgamation of the information available from all of the materials is possible and can include: social security numbers; credit card numbers; medical record numbers; health plan numbers; other account numbers of individuals; or biometric identifiers (fingerprints, retina, voice print, DNA, etc.).
How the Dataverse Software Works
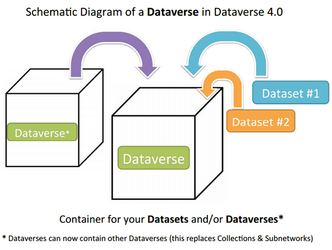
A Dataverse collection is a container for datasets (research data, code, documentation, and metadata) and other Dataverse collections, which can be setup for individual researchers, departments, journals, and organizations.
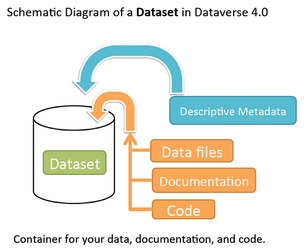
Each Dataverse collection contains datasets. Each dataset includes:
- Data files
- Metadata that describes the data files
Each dataset may also include:
- Code associated with the data files
- Additional documentation describing the data files and project form which they derive